
Ein*e Datenmanager*in beschäftigt sich mit allen Prozessen, die rund um die Erstellung, Speicherung und Pflege von Datensätzen ablaufen. Der größte Teil der Arbeit ist die Aufbereitung und Weitergabe von Daten. In der Theorie ist der Job als Datenmanager ganz einfach:
- Geschäftsanforderungen lesen,
- ETL Workflow bauen,
- vom Scheduler automatisiert laufen lassen
- und zurücklehnen.
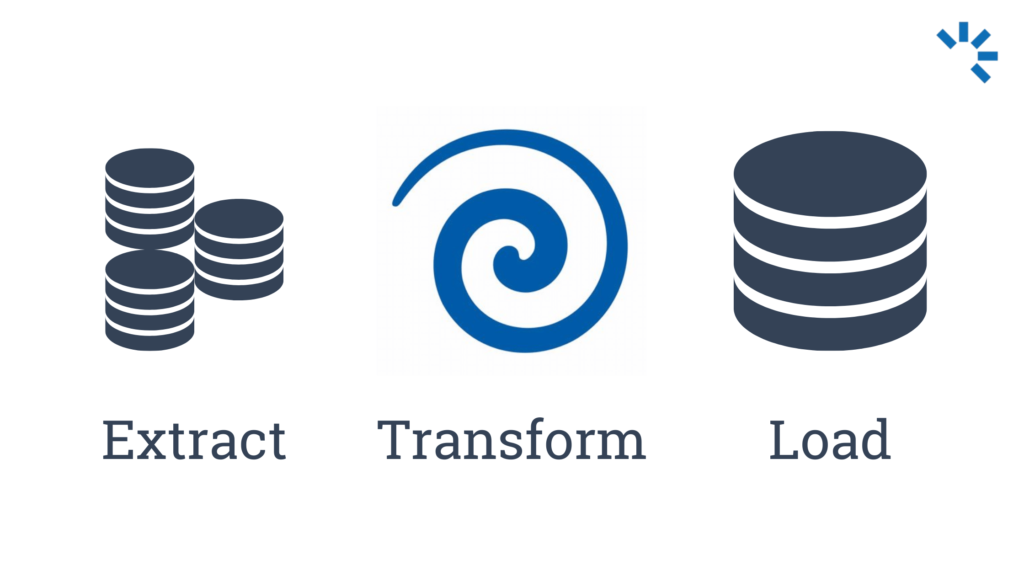
Ähnlich wie als Entwickler: User story lesen, Code schreiben und schließlich deployen. In der Realität sieht es leider nicht ganz so rosig aus. Dieser Artikel soll einen Einblick geben, mit welchen Herausforderungen ein Datenmanager tagtäglich zu kämpfen hat. Ein ETL Workflow beginnt mit einem Datensatz der aus einer Quelle extrahiert, dann passend zum Zielsystem transformiert und letztlich ins Zielsystem geladen wird. Solch ein Workflow kann wie folgt aussehen:
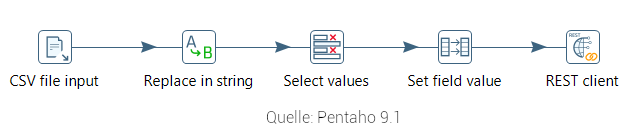
Sieht ganz einfach aus. Der Weg zu einem automatisierten Workflow ist jedoch weit und es kann einiges schiefgehen…
I) Quelle nicht gefunden
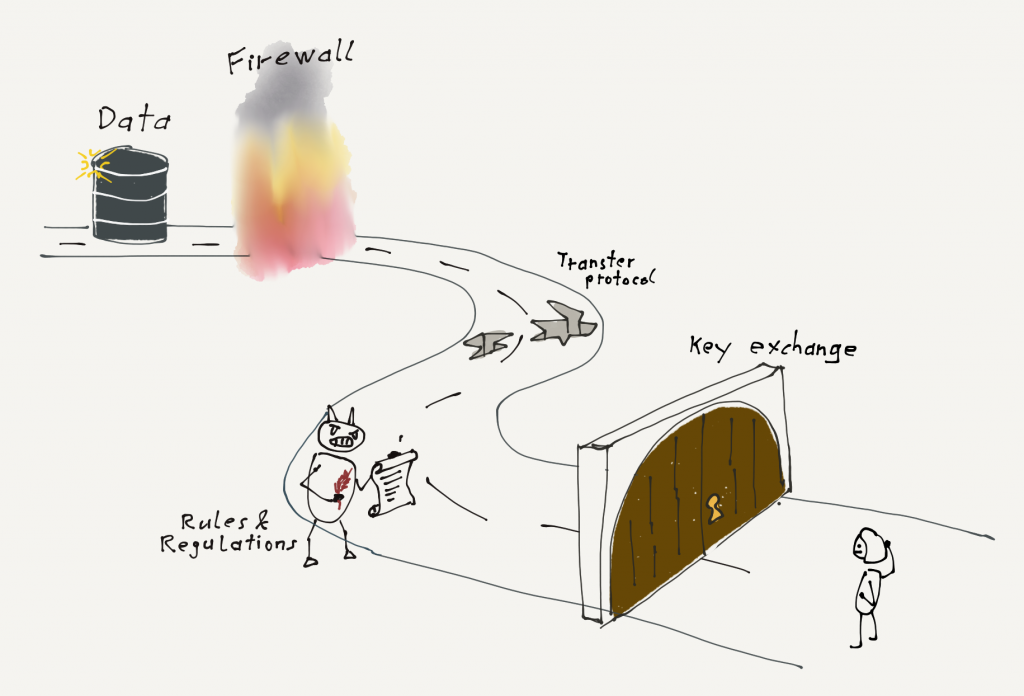
Um Daten zu extrahieren, muss man erst einmal an diese Daten rankommen. Dazu müssen sich die Partei des Quellsystems und der Datenmanager auf einen Übertragungsweg sowie ein Datenformat einigen. Anschließend müssen technische Hürden wie Firewall-Freischaltungen und der Austausch von Schlüsseln genommen werden. Da auf beiden Seiten viele verschiedene Parteien, wie Fachbereiche, IT-Sicherheit und Recht involviert sind, kann dies insbesondere in einem Großunternehmen schnell mehrere Monate dauern.
II) Datenmüll über den Zaun gekippt
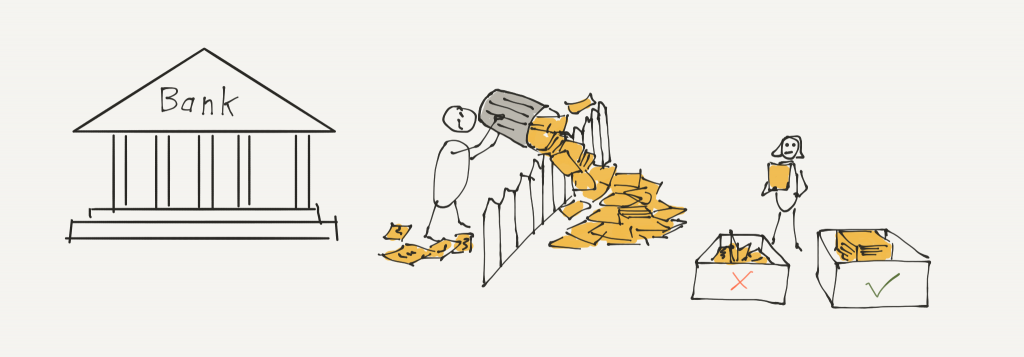
Man sollte meinen, dass durch den Zugriff auf die Daten die Extraktion ohne Weiteres umsetzbar ist. Schließlich hat man sich ja auf ein Datenformat geeinigt. Leider ist es die Regel, dass sich die echten Daten von den definierten Formaten unterscheiden: Hier fehlt eine Spalte, da steht Text anstelle von Zahlen, ASCI anstelle von UTF-8 als Kodierung usw. Jetzt muss der Datenmanager mit dem Troubleshooting beginnen, versuchen die Daten zu verstehen und irgendwie abzuleiten was eigentlich gemeint ist. Mit Glück kann die Partei des Zielsystems weiterhelfen. Manchmal kann es aber zur Mammutaufgabe werden jemanden zu finden, der sich auskennt.
III) Putzen was das Zeug hält
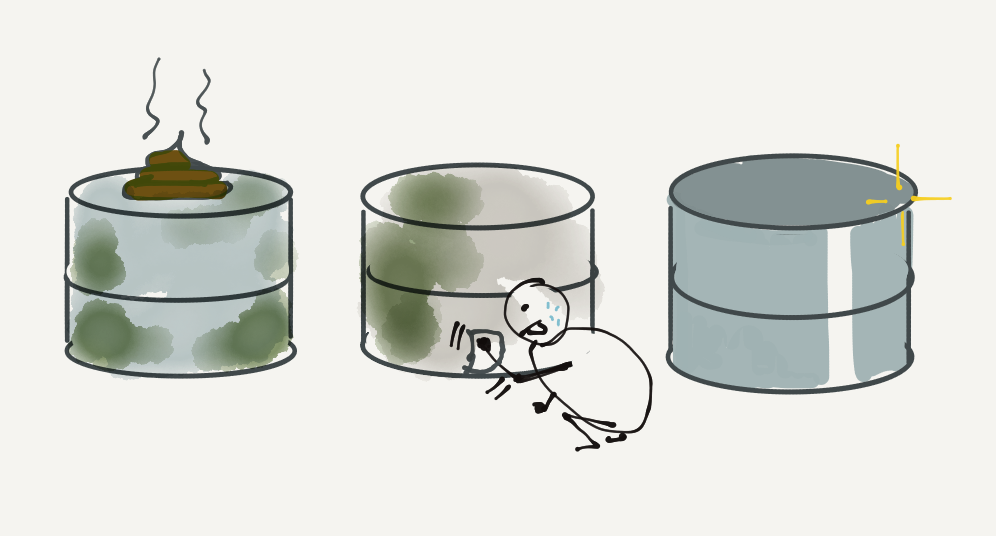
Sind die Quelldaten da, werden diese mit einem ETL Tool oder programmatisch gesäubert, transformiert und angereichert, sodass sie für das Zielsystem von Nutzen sind. Naturgemäß kommen Daten meistens als Textformat ohne Schema und müssen für die Weiterverarbeitung in entsprechende Datentypen transformiert werden. Dabei stellen sich dann interessante Fragen wie:
- Was ist das Datumsformat: DD/MM/YYYY oder MM/DD/YYYY?
- Wieso sind hier keine Werte obwohl diese Pflicht sind?
- Was ist das Dezimaltrennzeichen: Punkt oder Komma?
Zusätzlich sind viele Datensätze nicht brauchbar: Daten lassen sich nicht parsen lassen, weil z.B. in einer CSV-Datei Anführungszeichen nicht auskommentiert wurden oder es fehlen Spalten. Der Datenmanager entfernt nun die korrupten Daten oder entwickelt einen Workaround zur Vervollständigung der Daten. Eine sehr beliebte Fehlerquelle der Datenlieferanten ist das Öffnen und erneute Speichern von CSV Dateien mit Excel und diese anschließend zu verschicken. Dabei werden dann aus Datumsangaben Dezimalzahlen und unser Datenmanager darf die Datei erneut anfordern. Im besten Fall sollte die Datei in korrekter Form neu vom Lieferanten geliefert werden, allerdings dauert dies meist länger als die Entwicklung eines Workarounds.
IV) Mapping Business Key 105 zu Bank123 außer bei Vollmond, dann Bank08/15
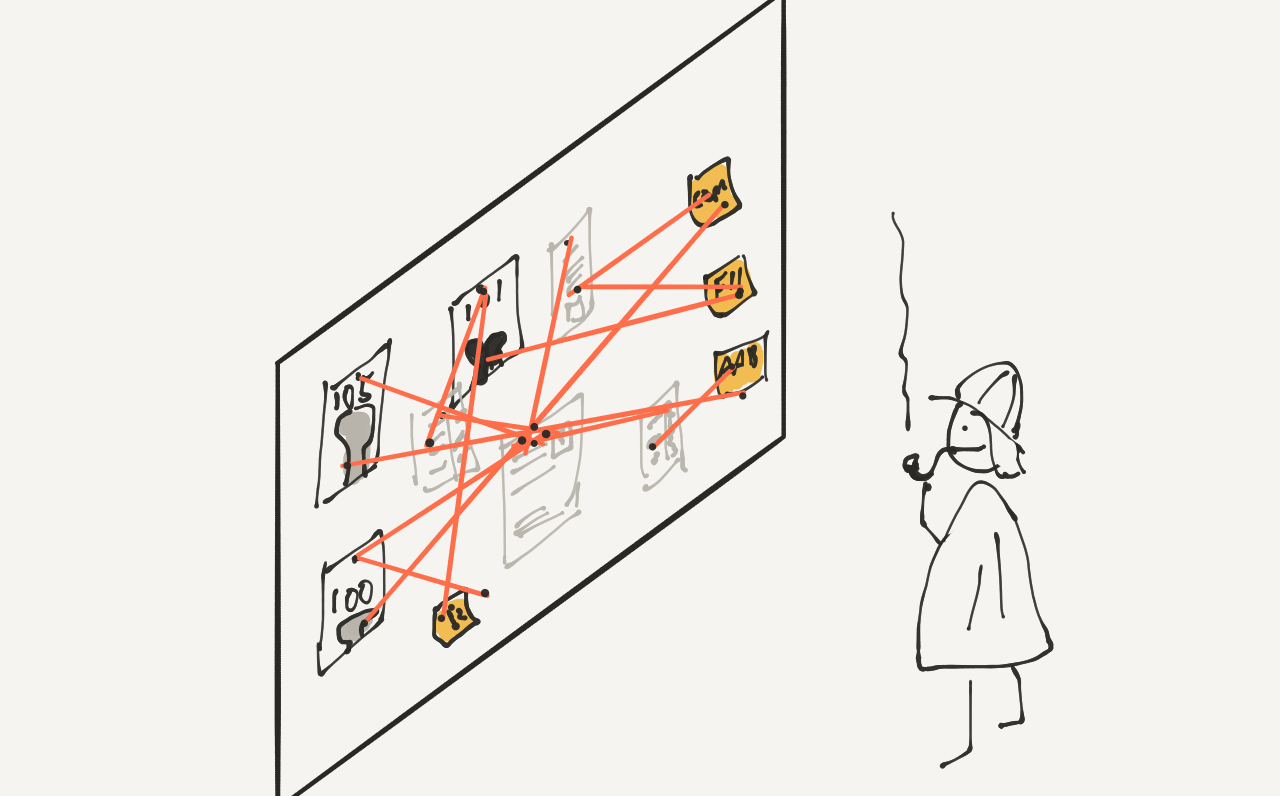
Meistens beinhalten Daten bestimmte Geschäftsschlüssel wie Transaktionscodes oder Kontotypen, die auf die internen gemappt werden müssen. Diese Mappings können nur durch den fachlichen Austausch mit dem Lieferanten erarbeitet werden, da häufig keine genaue Definition vorliegt, was genau sich hinter einem Schlüssel verbirgt. Dabei muss der Datenmanager ständig bedenken, dass sich die Codes jederzeit im Quell- als auch im Zielsystem ändern können und dann ein neues Mapping erstellt werden muss.
V) Duplicate entry ‘1234’ for key ‚unique_id‘
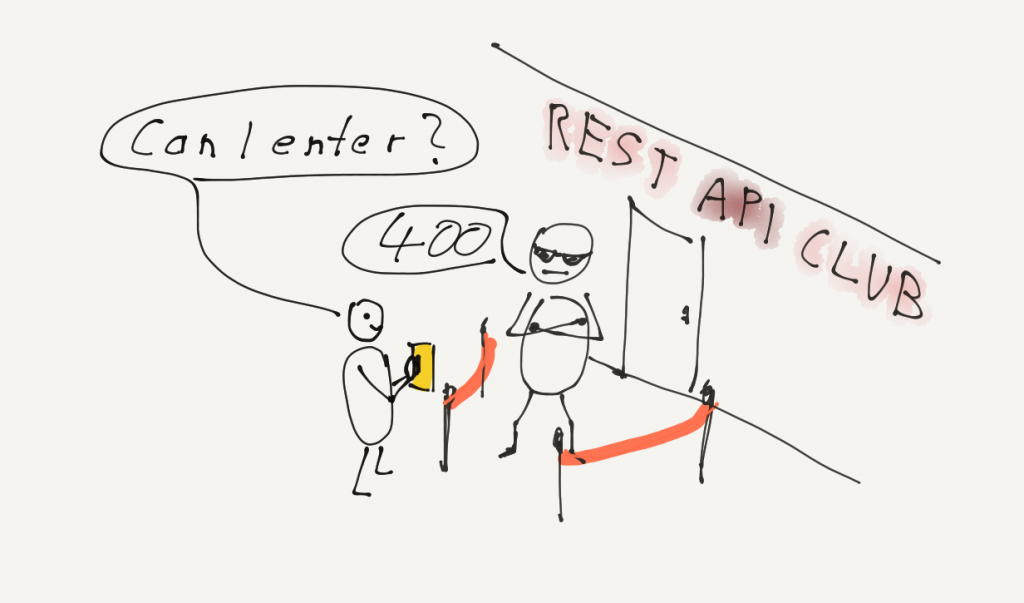
Sind die Daten vollständig gereinigt und transformiert, können sie in das Zielsystem geladen werden. Dabei kann es vorkommen, dass einzelne Datensätze nicht akzeptiert werden. Jetzt muss entschieden werden, ob der Gesamtbestand an geladenen Daten unbrauchbar ist und ggf. wieder aus dem Zielsystem entfernt werden muss, oder ob das Fehlen einzelner Datensätze vertretbar ist. Zusätzlich müssen die Daten manuell gepatcht werden, wenn es sich um wichtige Transaktionen handelt, die z.B. Zahlungsströme auslösen.
Hat der Datenmanager den Prozess durchlaufen, ist die erste Version des Workflows aufgesetzt und kann durch einen Scheduler automatisch ausgeführt werden. Kann sich der Datenmanager jetzt also entspannt zurücklehnen? Leider Nein. Alle Punkte können natürlich im laufenden Betrieb wieder auftauchen. Häufig ändert sich das eingehende Format ohne Ankündigung, das Zielsystem wird angepasst oder das interne Mapping ändert sich.
Für den Datenmanager gibt es ständig etwas zutun.
Fazit
ETL Workflows haben viele Abhängigkeiten zu mehreren externen Parteien, wodurch sich die Komplexität erhöht und die Berechenbarkeit reduziert. Wir haben nur einen kleinen Ausschnitt davon gesehen was alles bei der Entwicklung und dem Betrieb von ETL Workflows schiefgehen kann.
Damit das Datenmanagement weiter skalieren kann, muss auf die klare Definition von Schnittstellen und Prozesse und deren Einhaltung von allen Parteien geachtet werden. Durch technische Maßnahmen, wie Datenformate mit Schemainformationen und die Automatisierung wiederkehrender Prozesse, können bei gleicher Personenzahl viele weitere ETL Workflows betreuen. In einem nächsten Blogpost werden wir sehen welche Eigenschaften einen guten ETL-Prozess ausmachen.
Dadurch, dass es nicht soooo einfach ist, kann man am Ende umso „stolzer“ sein, wenn man die Mehrwerte der Daten allen Nutzern zugänglich macht. In diesem Sinne – DANKE!…und die Geschichte geht immer weiter und wird immer besser!
Mega cool, echt super Einblick!
Die Zeichnungen sind der Hit, besonders die mit Müll…
Moin Jan Erik, schöner Blog, gefällt mir. 🙂
Danke für den Einblick.